Clustering Tutorial#
Problem Statement#
Data does not typically come labeled and labeling/verifying labels is a time and resource intensive process. Exploratory data analysis (EDA) can often be enhanced by splitting data into similar groups.
Clustering is a method which groups data in the format of (samples, features). This can be used with images or image embeddings as long as the arrays are flattened to only contain 2 dimensions.
The Clusterer class utilizes a clustering algorithm based on the HDBSCAN algorithm and outputs outliers and duplicates.
When to use#
The Clusterer can be used during the EDA process to perform the following:
group a dataset into clusters
verify labeling as a quality control
identify outliers in your dataset
identify duplicates in your dataset
What you will need#
A 2 dimensional dataset (samples, features)
A python environment with the following packages installed:
matplotlib
This could be a set of flattened images or image embeddings. We recommend using image embeddings (with the feature dimension being <=1000).
Getting Started#
Let’s import the required libraries needed to set up a minimal working example.
import matplotlib.pyplot as plt
import numpy as np
import sklearn.datasets as dsets
from dataeval.detectors.linters import Clusterer
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1730287858.721133 9299 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1730287858.726963 9299 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
Loading in data#
For the purposes of this demonstration, we are just going to create a generic set of blobs for clustering.
This is to help show all of the functionalities of the clusterer in one tutorial.
# Creating 5 clusters
test_data, labels = dsets.make_blobs(
n_samples=100,
centers=[(-1.5, 1.8), (-1, 3), (0.8, 2.1), (2.8, 1.5), (2.5, 3.5)],
cluster_std=0.3,
random_state=33,
) # type: ignore
Because the clusterer can also detect duplicate data, we are going to modify the dataset to contain a few duplicate datapoints.
test_data[79] = test_data[24]
test_data[63] = test_data[58] + 1e-5
labels[79] = labels[24]
labels[63] = labels[58]
Visualizing the clusters#
# Mapping from labels to colors
label_to_color = np.array(["b", "r", "g", "y", "m"])
# Translate labels to colors using vectorized operation
color_array = label_to_color[labels]
# Additional parameters for plotting
plot_kwds = {"alpha": 0.5, "s": 50, "linewidths": 0}
# Create scatter plot
plt.scatter(test_data.T[0], test_data.T[1], c=color_array, **plot_kwds)
# Annotate each point in the scatter plot
for i, (x, y) in enumerate(test_data):
plt.annotate(str(i), (x, y), textcoords="offset points", xytext=(0, 1), ha="center")
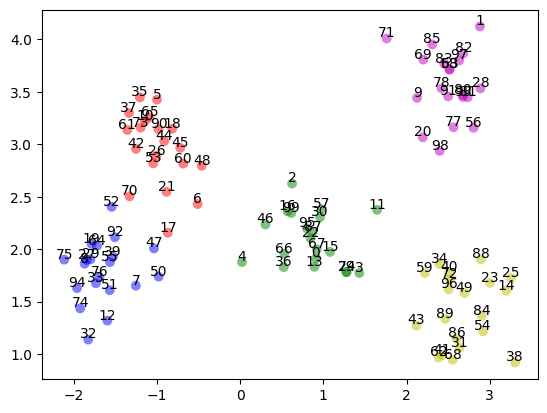
# Verify the number of datapoints and that the shape is 2 dimensional
print("Number of samples: ", len(test_data))
print("Array shape:", test_data.ndim)
Number of samples: 100
Array shape: 2
Running the Clusterer#
We are now ready to run the data through the clusterer and inspect the results.
# Initialize the clusterer
clusterer = Clusterer(test_data)
# Evaluate the data
results = clusterer.evaluate()
Results#
We can list out each category followed by the number of items in the category and then display those items on the line below.
For the outlier and potential outlier results, the clusterer provides a list of all points that it found to be an outlier.
For the duplicates and near duplicate results, the clusterer provides a list of sets of points which it identified as duplicates.
# Show results
for category, finding in results.dict().items():
print(f"\t{category} - {len(finding)}")
print(finding)
outliers - 6
[4, 6, 11, 21, 38, 71]
potential_outliers - 5
[1, 9, 42, 43, 48]
duplicates - 2
[[24, 79], [58, 63]]
potential_duplicates - 10
[[8, 27, 29], [10, 65], [16, 99], [19, 64], [22, 87, 95], [33, 76], [39, 55], [40, 72], [41, 62], [80, 81, 93]]
We can see that there was 6 outliers and 5 potential outliers. There was also 2 sets of duplicates and 10 sets of near duplicates.